

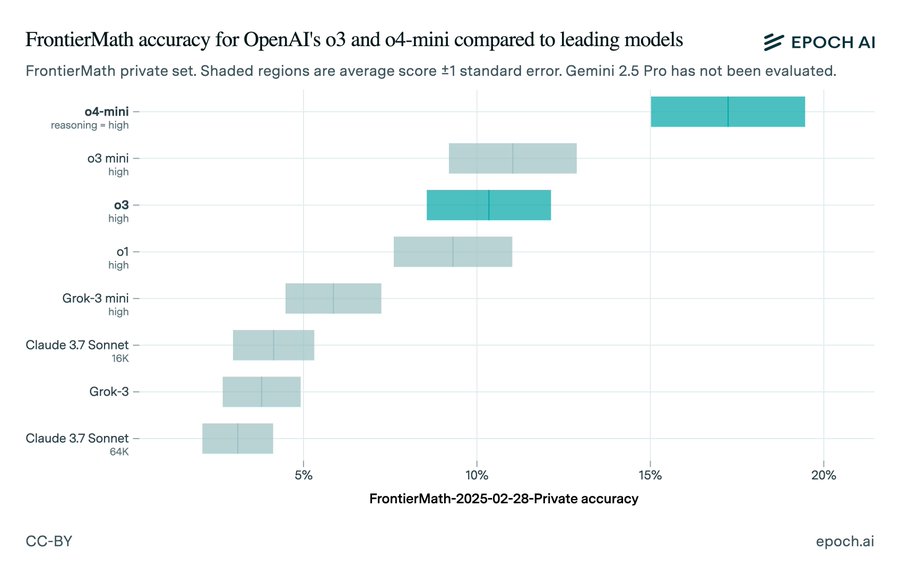
OpenAI o3 model reportedly fails to achieve the set benchmark initially proclaimed by the developing company. As per a recent report of Epoch AI, the model could reach only 10% of the score in FrontierMath problems, which was primarily claimed to be 25%.
Chaos takes place among the users and developers as the latest AI model by OpenAI is facing difficulties matching the benchmark scores. As a result, questions arise about the firm’s transparency and model development practices.
OpenAI launched the o3 AI model on April 16, 2025, alongside the o4-mini, integrating unmatched reasoning and multimodal understanding. As per the developing firm, o3 is their “most powerful reasoning model.” Alongside that, the new models are set to generate results on ChatGPT using Python code execution, web browsing, and image processing.
The development of the o3 model was announced in December 2024 when OpenAI claimed that the advancement would be able to solve increasingly difficult mathematical problems of FrontierMath. As per the assertion, the model could solve more than a fourth of the questions from the set of problems, reaching 25% of the score. Evidently, all the available models could only achieve 2% in the evaluation.
However, Epoch AI, a reputed research body, has found the OpenAI o3 model to score only around 10% in their benchmark assessment. The firm remarked, “OpenAI has released o3, their highly anticipated reasoning model, along with o4-mini, a smaller and cheaper model that succeeds o3-mini. We evaluated the new models on our suite of math and science benchmarks. Results in thread!”
What Concerns Does this Matter Raise?
The dissimilarity between OpenAI’s proclamation and Epoch AI’s recent test results has triggered transparency issues between the company and its user base. Many believe it to be a mere and unnecessary PR attempt that OpenAI previously committed during the launch of GPT-2. Epoch AI’s test results clearly show that the o3 model couldn’t match the desired and predefined outcome.
The situation also indicates issues with the regulatory frameworks of AI development, which question the accountability of the AI models. Such incidents impact user trust remarkably. As a consequence, individuals may not find such AI models reliable enough. Nevertheless, Epoch AI believes that its testing environment might vary significantly from that of OpenAI’s testing parameters. So, OpenAI may not have made false assertions on the performance of their latest AI model.
Attain knowledge of the latest technologies and trends with SecureITWorld!
Also Read:
What is ChatGPT, and What are its Key Benefits?
What is Perplexity AI Model? Is Perplexity AI Better than ChatGPT?

